关于Whitebox GAN的一些碎碎念
什么是Whitebox GAN?
Whitebox GAN网络最初发表于CVPR2020的论文Learning to Cartoonize Using White-box Cartoon Representations。其是一个将现实风格的图片(视频)转换为动漫风格的网络。
该网络改进了生成图片中的高频纹理和细节,获得了更好的图片动漫风格化的结果。
其代码开源在GitHub,可以下载已经训练完成的代码进行尝试~
该网络同样在B站上有效果展示!
网络结构
该网络采用了Generater-Discriminator结构,通过一个Generator网络实现从现实图片到动漫图片的风格域转换;同时,采用了两个Discriminator来进行甄别和训练。
Generator
Generator网络采用了一个标准的结构:三层down sample layer(下采样层),四层residual block(残差网络)和三层up sample layer(上采样层)。其中,从down sample layer到对应的up sample layer之间有对应的skip connection(跳跃连接),以便于捕捉到更多的信息。
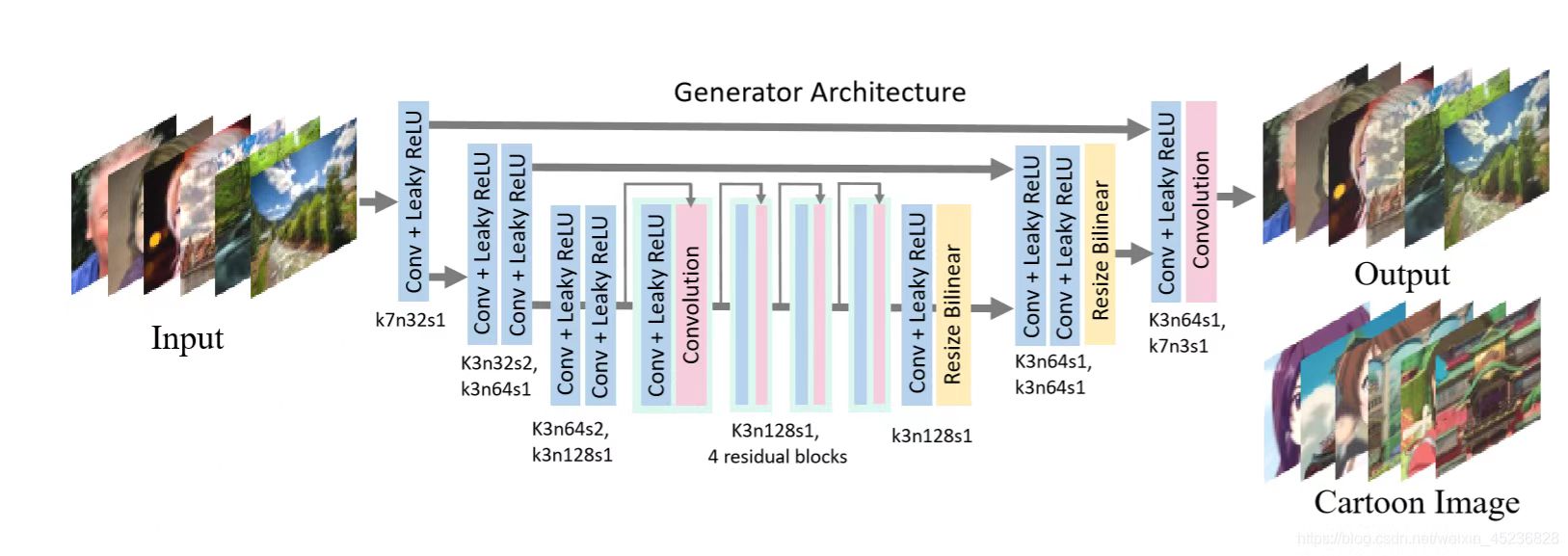
down sample layer
每个down sample layer采用了两个卷积神经网络:一个将分辨率减半并将channel翻倍,一个不变。其网络结构可表现为如下:
1 | nn.Conv2D(in_channels,out_channels,kernel_size=3,stride=2,padding=1), |
residual block
Residual block就是通过一个跳跃连接,将网络输出与最初的输入数据相加,并作为最终的结果输出。
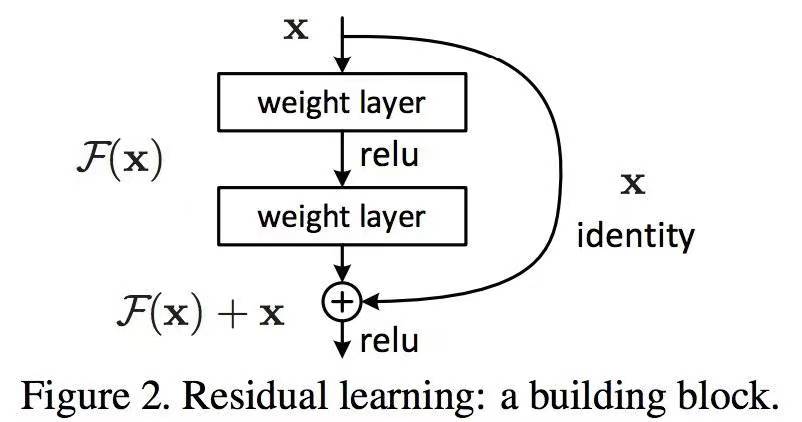
根据浅显的理解,可以认为是通过附加的网络来找到更隐藏的细节,同时保留了原有的数据,以便不影响之前已经找到的细节。
更正式的说,该网络是为了解决,当神经网络隐藏层过多时,网络会过饱和导致最终的准确率反而变低。因此,通过一个跳跃连接,可以做到增加层数而不丢失准确度。
其网络结构可以表达为如下:
1 | input: x |
up sample layer
与通常使用Conv2DTranspose来进行上采样的网络不同,每个up sample layer都是通过双线性插值来完成分辨率的提升的。
其可以理解为对目前拥有的feature先进行分辨率提升,再通过卷积神经网络丰富其细节。
其网络结构可表示如下:
1 | nn.Conv2D(in_channels,in_channels,kernel_size=3,stride=1,padding=1), |
您可能已经注意到了,以上的结构表示都是伪代码。不过相信您了解过一些pytorch的话,还是很容易看懂的!
Other
网络中同时有一些其他的用于连接的网络,在前图中已经表示的很明确了,在此不多赘述。
Discriminator
Discriminator的结构也比较标准:通过一系列的卷积神经网络不断寻找其中的feature,最后通过一个全连接的网络,获取到其认为真实的可能性。
需要注意的是,此处的卷积神经网络同时采用了“谱归一化”,即让卷积网络也成为L1-Lipschitz的。这部分可以直接Google“谱归一化”或"spectral norm",讲的很清楚。
loss_fn
loss主要由5部分组成:surface,texture,structure,content,tv
接下来会对每个loss进行详细描述:
surface loss
surface loss首先将图片输入进行平滑(采用导向滤波),以便去除纹理和细节特征。然后,通过一个discriminator来判断是否符合卡通图的特征。
在原文中使用的是GAN Loss,然而实际中L2 GAN Loss会更有优势,所以使用的是L2的。
其代码如下:
1 | surface_loss = conf["W_surface"] * lsgan_loss_g(surface_discriminator(guided_filter(pred))) |
texture loss
texture loss是将图片转为灰度图以便于忽略颜色和亮度的影响,然后通过另一个discriminator来判断其纹理和细节是否像一张卡通图。
注意与surface loss区别,这里并没有去除高频细节和特征。
对于图片转灰度,一般可以用以下的方式实现:将RGB三个通道通过不同的权重加权。
1 | ret=t[:,0]*0.299+t[:,1]*0.587+t[:,2]*0.114 |
loss代码如下:
1 | texture_loss = conf["W_texture"] * lsgan_loss_g(texture_discriminator(pred_gray)) |
structure loss
structure loss首先通过一个分割,将图片分成不同的区域。该分割最初可参考《effecient segmentation》这篇论文,不过一般程序中直接采用skyimage这个库来实现。
而之后,可以直接用一个现成的VGG网络,分别对分割后的原图和生成的图像特征差进行比对。其可以维持目标图的大致的区域特征被保留。
loss代码如下:
1 | pred_vgg = VGG(pred_seq) |
content loss
content loss则省去了分割的步骤,直接通过VGG判断两者的特征是否相似。这样可以维持从原图到目标图的内容完整性。
loss代码如下:
1 | pred_vgg = VGG(pred_seq) |
tv loss
tv loss则是希望图像输出尽可能的平滑,同时抑制高频噪声的出现。这样可以使生成图像更符合卡通图特征的同时,抑制噪声。
loss代码如下:
1 | dx = pred_seq[:, :, 1:, :]-pred_seq[:, :, :-1, :] |
Final
最后,通过调整每个loss的权重,得到最终的loss进行训练。
1 | surface_loss = conf["W_surface"] * \ |
效果
文章作者通过分类精度来和FID进行评价,发现相较于其它同类型模型效果上都有不错的表现。
同时,在日常风景转换方面效果不错;而人脸部分差强人意。可能可以通过添加训练集的方式进行改进。
完结撒花!

